Installing Tools within GitHub Actions Workflows (Deep Dive: GitHub Action Tool Cache)
Two of the most common use cases for GitHub Actions are:
- Running an application's test suite
- Building an application for release
Both usually require a language runtime and/or build toolchain.
This article explores how to do so optimally, which requires understanding and using the GitHub Actions Tool Cache.
The code samples from this article can be found at: https://github.com/sidpalas/tool-cache-deep-dive
This article was written as part of my preparations for the upcoming "GitHub Actions: Beginner to Pro" course I am working on.
See: https://github.com/sidpalas/devops-directive-github-actions-course for more info!
Aside: Ephemeral vs Stateful Runners
In most cases (including default GitHub-hosted runners), the environment where jobs are executed is ephemeral and lives only as long as the job it executes. This has many useful properties related to security, consistency/reproducibility, and scalability, but introduces inefficiencies related to installing dependencies.
Specifically, any changes to the system (such as installing a tool) are not persisted across jobs. Unless you are intentional about how you install and cache tools, it is easy to end up downloading and installing things with every workflow run, wasting both time and compute resources.
It is worth mentioning that self-hosted runners can be stateful and reused across jobs. In that case, a script that performs if not installed, then install is sufficient. The rest of the article assumes you are using an ephemeral runner.
What is the Tool Cache?
The tool cache is a well-known directory inside every runner where “setup-x” actions (e.g. https://github.com/actions/setup-node) check for and install versioned tool payloads. There are two official locations:
| OS | Default Path |
|---|---|
| Linux / macOS | $RUNNER_TOOL_CACHE → /opt/hostedtoolcache/ |
| Windows | %RUNNER_TOOL_CACHE% → C:\hostedtoolcache\windows\ |
Within that directory, tools are stored using a directory structure like (using Node.js as an example):
$ tree /opt/hostedtoolcache/node -L 2
node/
`-- 20.19.3
|-- x64 -> /bin/node
`-- x64.complete # indicates that install is complete and ready for use
The path to the tool encodes the version and architecture (x64, arm64), and a .complete file indicates the tool is installed and ready for use.
Despite being named "cache", the tool cache is not automatically shared across jobs (see section about ephemeral runners above).
@actions/tool-cache npm package
The @actions/tool-cache npm package provides utilities for checking if a tool exists within the cache as well as downloading and extracting in platform specific ways.
For example, to check if a specific version of Node.js exists within the cache you can use the find function:
const tc = require('@actions/tool-cache');
const nodeDirectory = tc.find('node', '12.x', 'x64');
This package is used by the setup-x actions to ensure consistency when setting up necessary tools.
How do actions/setup-x actions work?
The official setup-x actions generally follow the same pattern:
- Look in
$RUNNER_TOOL_CACHE/<tool>/<version>/<arch>for a folder marked.complete. - If present, configure the environment to use it
- If absent, it downloads the tool, unpacks it into that same path, drops the .complete sentinel, and then adds the folder to PATH — seeding the cache for any later steps or jobs that run on the same runner.
What are my options?
Option 0: Use pre-installed versions + setup-x actions
Many popular tools come preinstalled on the runner image (see: https://github.com/actions/runner-images). For example the ubuntu-24.04 image contains:
- Language runtimes:
- Node.js 20.19.3
- Python 3.12.3
- Popular CLIs:
- AWS CLI 2.27.50
- GitHub CLI 2.75.0
- Lots more!
If you are willing and able to use the preinstalled version, this is ideal! You can generally use one of the official actions/setup-x actions (e.g. https://github.com/actions/setup-node) and it will:
- Identify that the desired version exists
- Skip the installation step
Here is an example job using the preinstalled Node.js version via actions/setup-node:
jobs:
preinstalled:
runs-on: ubuntu-24.04
steps:
- uses: actions/setup-node@v4
with:
node-version: 20 # This will use any major version match (e.g. 20.x.x)
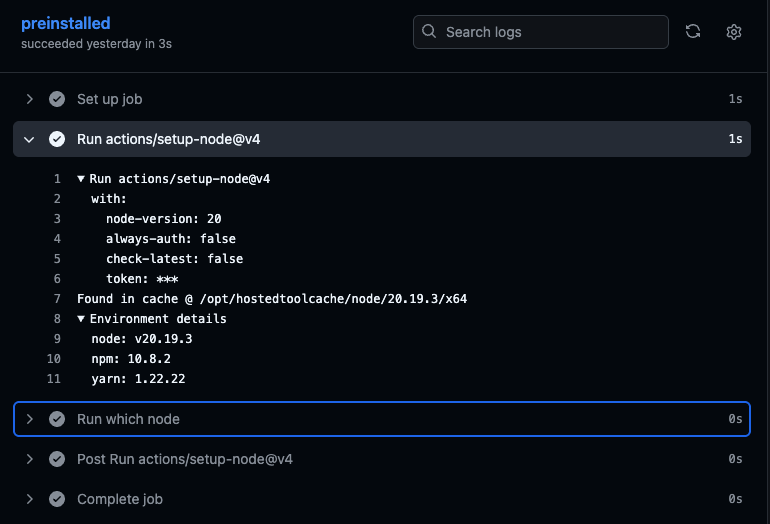
Using the pre-installed version, setup-node executes in just 1 second!
Option 1: Install with each run
If you need a different version, you can tell setup-x to use the desired version, but this will cause the tool to be re-downloaded and re-installed with each run.
Here is an example job pinned to a different version of Node.js not available in the runner image by default:
jobs:
older-version:
runs-on: ubuntu-24.04
steps:
- uses: actions/setup-node@v4
with:
node-version: 20.19.2
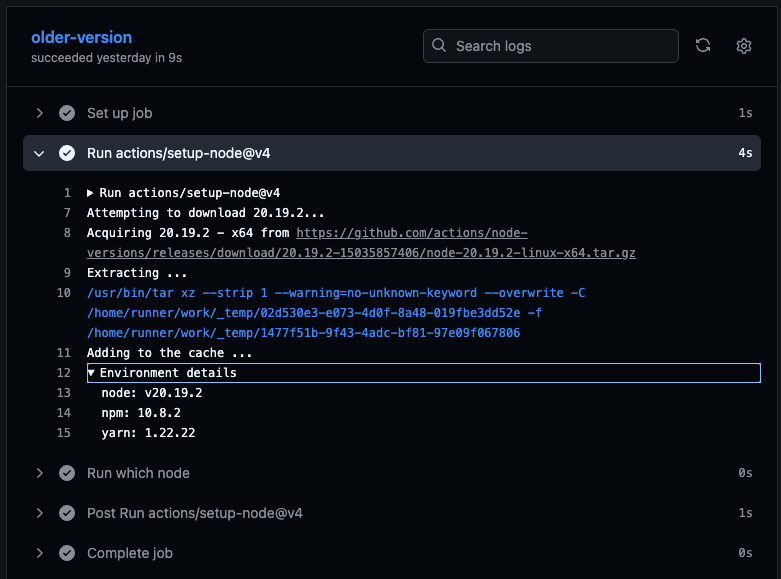
In the event of a cache miss, the action downloads from the upstream release
Option 2: Cache manually (via actions/cache)
One way to reuse the tool across ephemeral runners is to cache (and restore from cache) using actions/cache.
This avoids needing to download from the upstream release, but downloading from the GitHub actions cache isn't much faster than downloading the release directly.
Here is an example job caching and restoring a non-default version:
older-version-gha-cache:
runs-on: ubuntu-24.04
env:
NODE_DIR: /opt/hostedtoolcache/node/20.19.2/
steps:
- name: Restore Node from cache
id: cache-task
uses: actions/cache@v4
with:
path: ${{ env.NODE_DIR }}
key: node-20.19.2-${{ runner.os }}-${{ runner.arch }}
- uses: actions/setup-node@v4
with:
node-version: 20.19.2
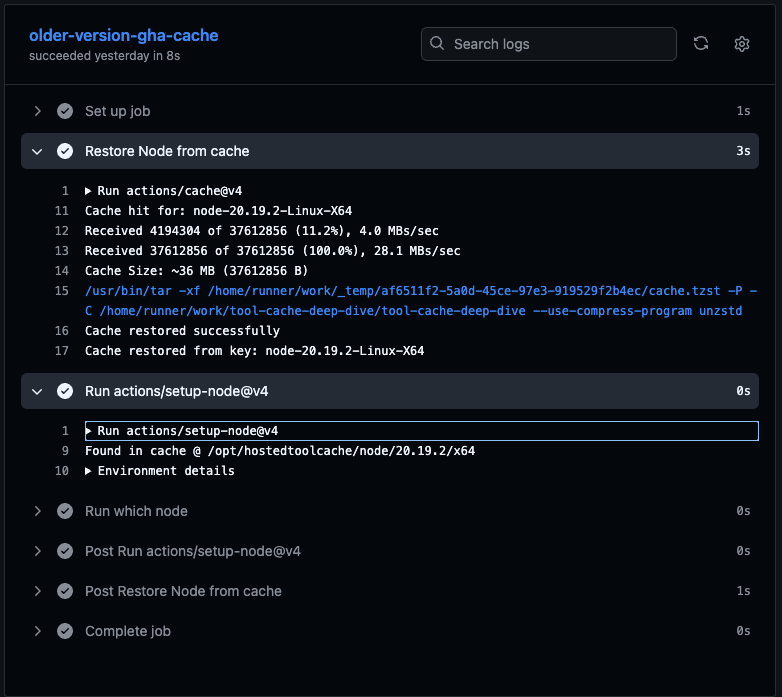
Restoring from the GitHub cache takes approximately as long as downloading the release directly
Option 3: Use another caching mechanism (e.g. Namespace Cache Volumes + toolchain caching)
If GitHub Action caching isn't much faster than the naive "reinstall every run" approach, is there a faster caching option we can use?
Namespace Labs provides one such option with their cache volumes. These are built on NVMe attached to their hosted runners which you can configure for their hosted runners.
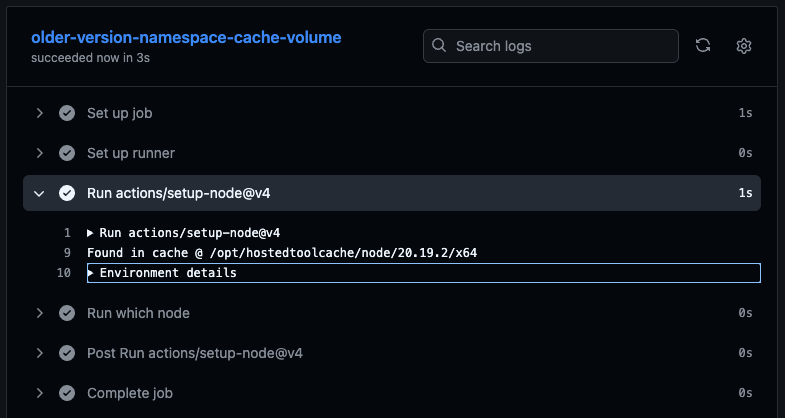
One option when configuring these cache volumes is whether or not to cache toolchain downloads. When enabled, Namespace will automatically cache tools stored according to the tool cache conventions for use in future runs.
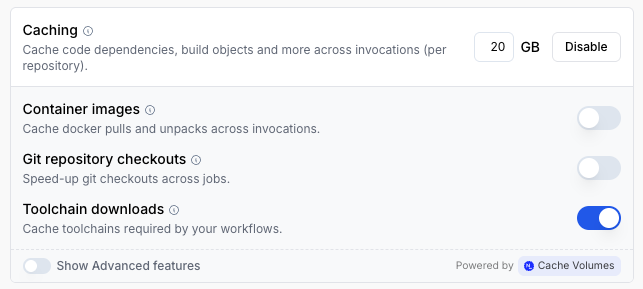
On the GitHub Actions workflow side, the only necessary change is to use the corresponding runner name in the runs-on field for the job:
jobs:
older-version-namespace-cache-volume:
runs-on: namespace-profile-toolchain-volume-cache
steps:
- uses: actions/setup-node@v4
with:
node-version: 20.19.2
Namespace Labs is sponsoring my upcoming GitHub Actions course, but this post is not sponsored.
Option 4: Use a custom Container Image or AMI
If you want to avoid dealing with setup-x altogether, you can run your jobs inside of a container or virtual machine preconfigured with the desired tool version(s).
Container
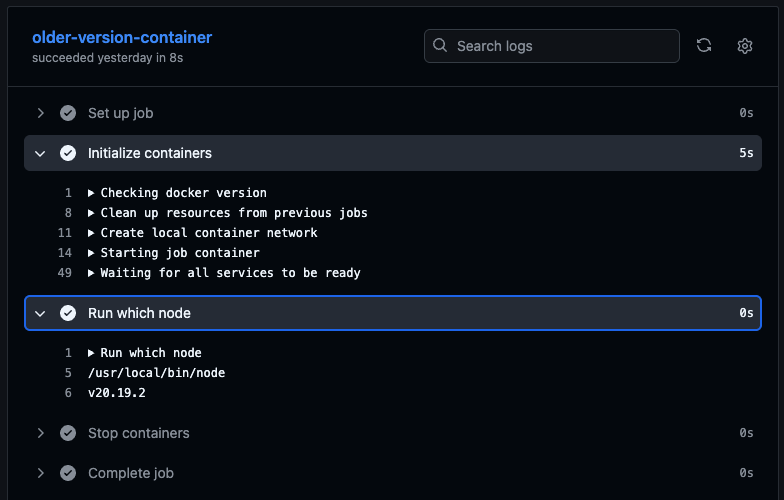
GitHub Actions provides the option to run your jobs inside of a container with an image of your choosing.
One downside to this approach is that running the container introduces its own initialization overhead.
Here is an example job using this option:
jobs:
older-version-container:
runs-on: ubuntu-24.04
container:
image: node:20.19.2-alpine
steps:
- run: |
which node
node -v
If you are self-hosting runners via the actions-runner-controller you could similarly use a container image preconfigured with the desired tools.
Virtual Machine
If you are self-hosting runners as virtual machines, such as with runs-on, you can build the virtual machine image (e.g. AMI if on AWS) with the desired tools using a tool like Packer
Option 5: Do everything within the Dockerfile
Similar to using a custom image for the runner, we can bypass the need to use the tool-cache entirely by performing all of the necessary build/test actions within the container build process.
This can be accomplished via a multi-stage build, with specific build targets which do things like execute the tests:
# Dockerfile
FROM node:20.19.2-bookworm-slim AS base
WORKDIR /usr/src/app
COPY package*.json ./
###################################
FROM base AS which-and-version
RUN which node && node -v
###################################
FROM base AS test
RUN npm ci
COPY ./src/ .
ARG FAIL_OR_SUCCEED
RUN npm run test-${FAIL_OR_SUCCEED}
###################################
FROM base AS deploy
ENV NODE_ENV=production
RUN npm ci --production
USER node
COPY --chown=node:node ./src/ .
EXPOSE 3000
CMD [ "node", "index.js" ]
{
"name": "tool-cache-deep-dive",
"version": "1.0.0",
"description": "",
"homepage": "https://github.com/sidpalas/tool-cache-deep-dive#readme",
"bugs": {
"url": "https://github.com/sidpalas/tool-cache-deep-dive/issues"
},
"repository": {
"type": "git",
"url": "git+https://github.com/sidpalas/tool-cache-deep-dive.git"
},
"license": "ISC",
"author": "",
"type": "commonjs",
"main": "src/index.js",
"scripts": {
"test-succeed": "echo \"This mimics a passing test suite... ✅\" && exit 0;",
"test-fail": "echo \"This mimics a failing test suite... ❌\" && exit 1;"
},
"devDependencies": {
"noop": "^1.0.1"
}
}
The full example can be found at https://github.com/sidpalas/tool-cache-deep-dive.
By targeting the test stage we can then execute our tests within the container. For example:
➜ tool-cache-deep-dive git:(sp/initial-workflow-development) docker build --build-arg FAIL_OR_SUCCEED=fail . --target=test ...
=> ERROR [test 3/3] RUN npm run test-fail
------
> [test 3/3] RUN npm run test-fail:
0.168
0.168 > tool-cache-deep-dive@1.0.0 test-fail
0.168 > echo "This mimics a failing test suite... ❌" && exit 1;
0.168
0.170 This mimics a failing test suite... ❌
------
Dockerfile:14
--------------------
12 | COPY ./src/ .
13 | ARG FAIL_OR_SUCCEED
14 | >>> RUN npm run test-${FAIL_OR_SUCCEED}
15 |
16 | ###################################
--------------------
ERROR: failed to build: failed to solve: process "/bin/sh -c npm run test-${FAIL_OR_SUCCEED}" did not complete successfully: exit code: 1
Closing Thoughts
I wrote this article mostly because I found the existing documentation around the GitHub Actions tool cache to be lacking. Hopefully this gives you ideas for how to install tools required by your GitHub Actions workflows without incurring a significant time penalty.
Whether sophisticated caching is “worth it” comes down to the trade-off between complexity and time saved. Heavy toolchains (e.g. large Java distributions) can add significant time to every job. Every fresh download also introduces another external dependency: if the upstream mirror hiccups, your entire pipeline stalls.
I would generally take the following approach:
- If the runner contains an acceptable version preinstalled, use it!
- If you must pin a different version and you control self-hosted runners, a persistent cache volume (e.g. Namespace Labs cache volumes, ARC PVC, or similar) gives you the same performance with almost no extra YAML.
- When you’re already packaging and deploying containers, baking the runtime into the image keeps all dependencies self-contained and guarantees reproducibility across every environment.
Start with the lightest solution, determine how long it takes, and add caching techniques when the saved time outweigh the added complexity.