Velero AWS Account Migration [Case Study]
TL;DR: I recently helped an organization migrate a set of applications deployed in Kubernetes (EKS) across AWS accounts using Velero. This case study describes that process.
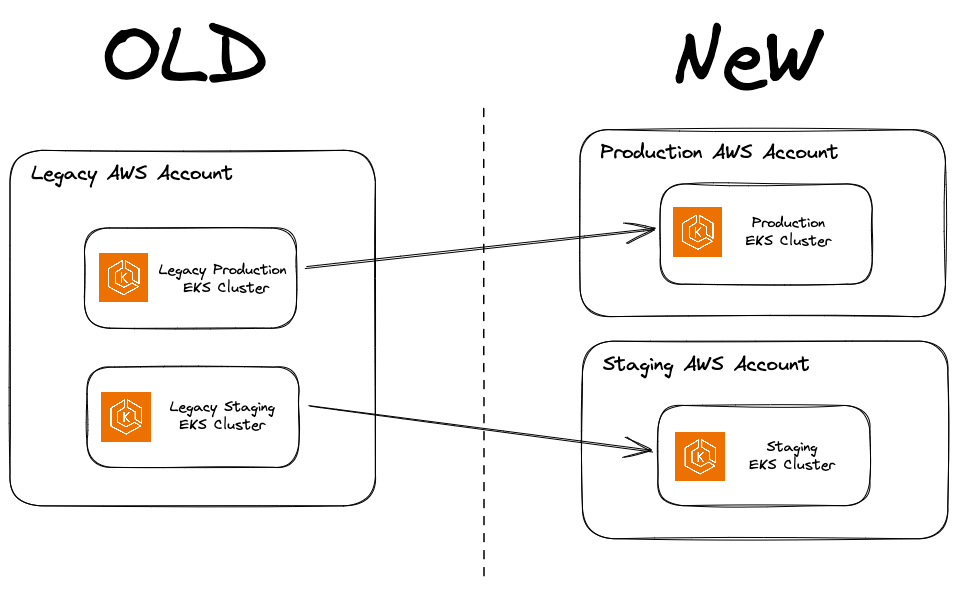
Please start with multiple AWS accounts so you don't have to hire someone like me to help with this! 🙏
Summary
The migration of Kubernetes clusters across different AWS accounts can be a challenging process, given the intricacies and dependencies that exist within each environment.
I recently used Velero to help an engineering organization migrate two EKS clusters (representing their staging and production environments) from a single AWS account to two separate accounts. I’ll delve into the migration process, share our experiences, and outline some lessons learned along the way.
Background
Each environment consisted of a variety of AWS resources (e.g. S3 buckets, RDS instances), some externally hosted databases (MongoDB Atlas, Neo4j Cloud), and a variety of microservices running in an EKS cluster.
These microservices can be categorized into the following groups:
- Job Producers: Detecting or receiving events from data vendors about new data to be processed or initiating periodic analytics jobs. These create messages containing the necessary metadata and send them to the Message Bus
- Message Bus: RabbitMQ cluster serving as a message bus for the system
- Job Consumers: Worker deployments that consume messages from the Message bus and perform the corresponding processing task (storing the associated data in S3 and/or databases)
- Other: Public facing web portal (nginx), various APIs, etc… These services were generally stateless and the primary consideration with respect to the migration is ensuring their configuration (loaded from ConfigMaps/Secrets were updated appropriately when started in the new clusters)
The applications were deployed into the cluster automatically using a pushed-based approach from GitLab CI/CD pipelines.
Primary Goals
- Migrate clusters to new accounts
- Minimize customer-facing downtime
- Avoid data loss or duplication
Migration Approach
Migrating Non-Kubernetes Resources
This case study is focused on using Velero for the Kubernetes workloads, but a brief description of the migration of other resources is useful context. Key points:
- Cloud Development Kit (CDK) configurations were built to provision copies of all the AWS resources in the new accounts.
- S3 replication was used to copy data (historical and ongoing) to new buckets.
- AWS DMS was used to copy data (historical and ongoing) to new RDS instances.
- External databases (MongoDB Atlas + Neo4j Cloud) were left in place and VPC peering was used to enable connectivity from VPCs in the new accounts. Note: This was simpler than migrating to new instances but did introduce the potential for legacy and new clusters to be attempting to write to them duplicate data to them.
Migrating Kubernetes Resources
We considered three methods for migrating the Kubernetes-based workloads:
-
Redeploy everything from GitLab
Deployments were automated via GitLab CI/CD, so one option would be to update the GitLab environment to point to the new cluster and trigger the latest deployment pipeline for each service. This is a simple approach and doesn’t require any new tooling, but there are many repositories, and not 100% of the resources in the cluster was deployed in this way.
-
Backup/restore with Velero
Another option would be to take a Velero backup in the legacy cluster and then restore that backup in the new cluster. Cluster migration is one of the stated use cases for Velero, but it does represent another tool to learn/install/configure if you are not already using it for backups.
-
Use a GitOps Approach
Using a tool like ArgoCD or FluxCD installed into the would provide a clean mechanism to pull the latest configuration for all of the applications from GitLab into the new cluster. This would require rolling out GitOps before performing the migration and would not work for any workloads not fully described in GitLab.
We decided to use Velero as it provided the simplest approach that would work even for resources that weren’t fully represented in GitLab or if we temporarily needed certain resources to differ from Git. For example ConfigMaps with references to S3 buckets or secrets containing RDS credentials. Also, we had recently set up Velero in the existing clusters as a backup solution, so the team was already familiar with its usage.
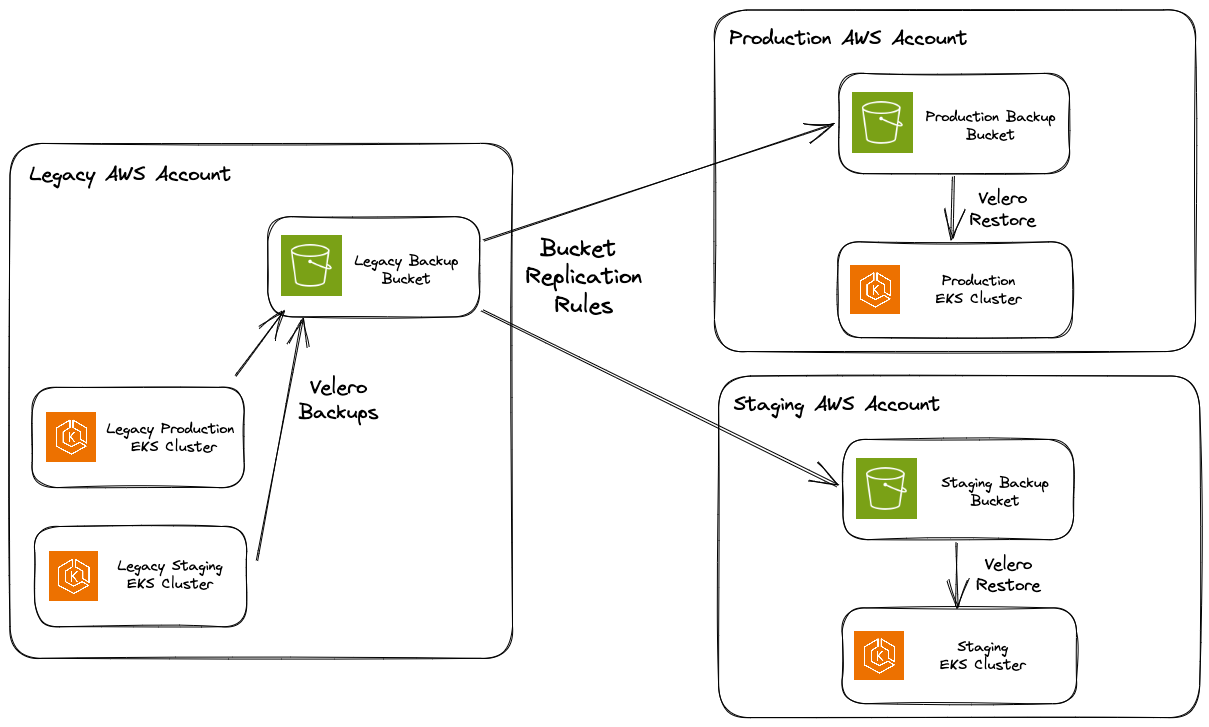
S3 configuration for replicating backups across accounts
Note: We did consider migrating applications one at a time, but this would require adding significant complexity in temporary configurations to support cross-AWS account IAM and networking and we decided to move everything at once to avoid this and prevent a potentially long period where the system lived in a partially migrated state.
Migration Sequence
The following is the sequence we used for the migration:
-
Install Velero into both clusters: Each bucket used a separate S3 bucket located in the AWS account where the cluster lived.
-
Set up S3 replication rule to copy backups between buckets: This is one place our process differs from the described Velero migration documentation because the clusters live in different AWS accounts. Rather than set up the necessary IAM for the new cluster to access the legacy bucket, we opted to replicate the backup data from the legacy bucket into the new one.
-
Scale down “Job Producers” in legacy cluster (This is highly specific to our application and migration plan): In order to avoid the potential for data loss and duplication we decided that the best approach would be to scale the job producers to zero and allow time for the job consumers to finish processing active jobs. Luckily, these data processing jobs are not directly visible to end users and therefore can be disabled temporarily without incurring customer-facing downtime.
-
Trigger backup in legacy cluster: Nothing special here, we created a backup from a schedule.
-
Deploy modified ConfigMaps and Secrets to new cluster: Many of the application consume their configuration from ConfigMaps and Secrets. When running in the new cluster they needed to use the new S3 buckets, RDS instances, etc. Velero by default does not overwrite existing Kubernetes objects, so pre-populating these resources would ensure they have the appropriate configuration when the corresponding applications are restored. We had open Merge Requests (or modifications to GitLab Secrets) containing all of these differences ready to Merge after the migration was complete to avoid reverting with the next deployment.
-
Restore from backup in new cluster: Again nothing special, we restored from the backup.
-
Scale up “Job Producers” in new cluster: Scaling the job producers back to their normal replica counts and cron schedules enables them to resume where they left off in the legacy cluster
-
Validate workload performance: We defined a number of checks to determine that critical workloads were healthy in the new cluster
-
Cut over DNS for external traffic: Once we were satisfied that things were behaving as expected, we cut over external DNS for the public apps/APIs
-
Update GitLab to deploy to new cluster: We updated the GitLab environment such that future deploys would target the new cluster instead of the legacy one.
Lessons Learned during the Migrations
All things considered, the migration went well! That being said, there were some hiccups related to Velero configuration details that are worth highlighting.
Velero doesn't back up cluster-scoped resources for namespace backups
Our Velero backups were scoped to specific Kubernetes namespaces (for reasons that are not relevant here). However, namespace-scoped backups do not back up cluster resources by default. This seems obvious in hindsight… but we had not accounted for it.
This caused certain CRDs our applications relied on to not be migrated. We identified this issue during the staging migration and updated one of the backup configurations to include the --include-cluster-resources=true option.
Velero backs up Pods by default
The default behavior for Velero is to back up all resource types, including Pods. For most applications this behavior is fine, but for certain stateful applications, the ordering of pod creation matters. In our case, our RabbitMQ cluster came up split-brained.
Because of how we opted to scale down/up the job producers we decided it was not necessary to snapshot and migrate the persistent volumes associated with RabbitMQ. Velero backed up three pods and those pods were restored simultaneously in the new cluster. Each of them started, failed to find a leader amongst its peers, and declared itself the leader. Instead of having one cluster with three instances, we had three clusters with one instance each, behind Kubernetes Service which dutifully load-balanced requests across them.
Unfortunately, we did not catch this during the staging migration because staging had been running with a single RabbitMQ replica (keep your environments identical people!) but by manually modifying the Service selector and labels on the pods we were able to systematically shift all traffic to one instance at a time and allow active jobs to be processed, eventually removing the separate instances, and finally scaling back to the desired single cluster configuration.
This issue could have been avoided by either (a) configuring Velero not to back up Pods directly so that the Statefulset would bring up the replicas one at a time OR (b) snapshot and migrate the persistent volumes so that the previous clustering information would also be migrated (this would present additional challenges of copying EBS volumes across AWS accounts and modifying the backup files to reference the new volume names/IDs).
Conclusion
Velero helped us streamline the migration of workloads between EKS clusters in separate AWS accounts. It is important to understand your specific backup configuration and how it might impact our system, also having a representative environment to test the environment can help identify issues before they reach your production environment.
In the end, the key to moving Kubernetes clusters successfully comes down to planning, knowing your workloads, and understanding your tools. This case study provides a glimpse into our journey and might help others who are about to do the same. We hope you can learn from our experience and avoid some of the challenges we faced.