Why Does Kubneretes Exist?
August 28, 2022
Categories: Tags:TL;DR: Kubernetes is complex because it is solving complex problems. It builds on multiple decades of progress to provide a solid foundation for deploying web applications!
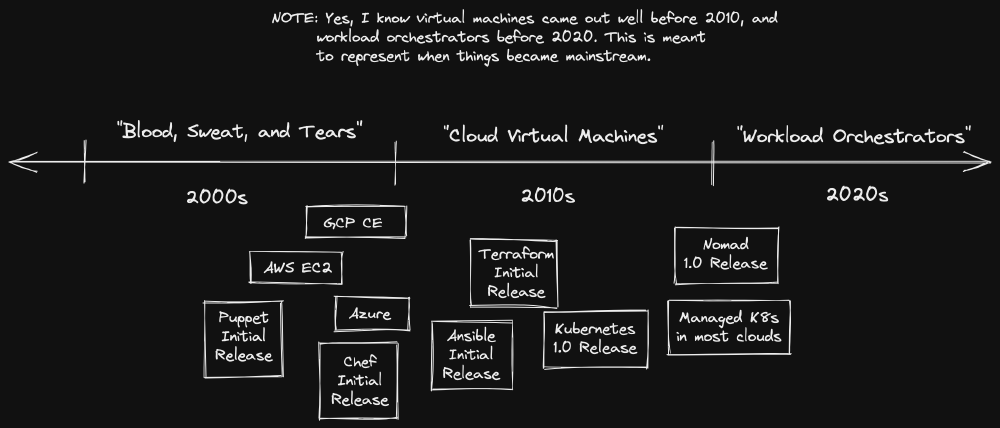
Table of Contents:
- Pre-Cloud (2000s)
- Virtual Machine + Configuration Management (2010s)
- Workload Orchestrators (Late 2010s -> Today)
- Video Summary
Pre-Cloud (2000s)
In the early days of the web, modern clouds didn’t exist (AWS started in 2006), but deploying web applications still required access to servers!
You either racked them yourself or rented them from a colocation facility, but either way, they were slow to procure and painful to manage!

The tooling to manage large fleets of servers and applications simply didn’t exist, so you would often hire a team of system administrators, who would end up rolling their own tooling in the form of Bash or Batch/PowerShell scripts! Also, because the applications were running directly on the host system(s), dependency management was a nightmare!
These factors pushed teams to use monolithic architectures because it was simply too hard to manage anything else. Doing zero downtime deployments with this type of setup was incredibly difficult, so many companies leveraged scheduled maintenance windows to handle updates and roll out new versions.
Virtual Machine + Configuration Management (2010s)
Once cloud providers started maturing, the concept of creating and destroying Virtual Machines in minutes is a paradigm shift. Rather than maintain long-lived servers you could tear down the old ones and replace them!
Also, configuration management tools like Puppet and Chef matured, helping make it possible to manage fleets of servers more easily!
Virtualization technologies provide a level of isolation between applications that alleviate some of the dependency hell from before!
As web applications started tackling more complex problem domains, sometimes team size caused teams to start moving away from monolithic architectures. The improved tooling of the cloud made it possible to carve things up into smaller pieces.
However, because the size and complexity of these systems were now larger, we needed improved tooling to help automate deployments, monitor application health across all of those machines, aggregate logs, etc…
Workload Orchestrators (Late 2010s -> Today)
Moving towards the late 2010s and into the present day, solutions to those challenges have emerged in the form of what we now call “Workload Orchestrators”.
There are a number of these types of systems:
- Docker Swarm
- Apache Mesos
- Hashicorp Nomad
- Kubernetes (today’s industry darling)
These provide APIs to abstract away the individual machines and instead treat a cluster of instances as a single resource pool.
You provide information about the types of resources our workloads require and then let the system decide how to schedule and run them!
Kubernetes provides things like:
- Automated health checks
- Deployment strategies to enable zero downtime deployment (+ rollbacks)
- Autoscaling based on metrics
- Standard interfaces for networking, storage, and runtimes
Before these systems were available, large companies were building them internally in private.
Luckily for us, a few of those companies decided to release their systems. Google took many of the ideas from their internal system “Borg” and started the Kubernetes project!
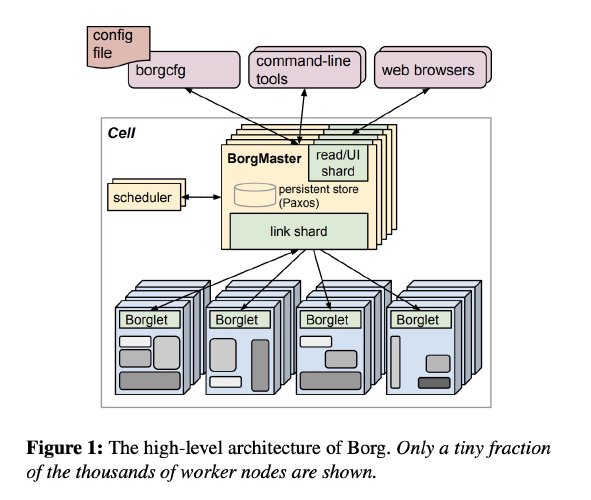
Now, rather than provisioning a bunch of instances/autoscaling groups for each app, you can provision a cluster and deploy many heterogeneous workloads into it!
You leverage the well-tested utilities of the system to handle what used to be done with your home-grown scripts.
So, yes Kubernetes IS quite complex, but that is because it is attempting to solve a complex problem!
Hopefully, this brief look over the past two decades has helped to give you an appreciation for why Kubernetes exists and operates the way it does.